Introduction to Pattern Matching
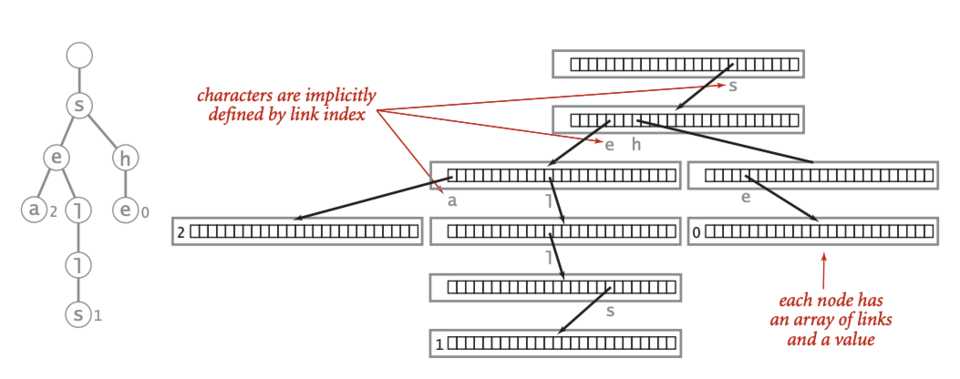
Trie representation from Wikipedia
{kind=link}
This problem asks:
Given: A list of at most 100 DNA strings of length at most 100 bp, none of which is a prefix of another.
Return: The adjacency list corresponding to the trie T for these patterns, in the following format. If T has n nodes, first label the root with 1 and then label the remaining nodes with the integers 2 through n in any order you like. Each edge of the adjacency list of T will be encoded by a triple containing the integer representing the edge’s parent node, followed by the integer representing the edge’s child node, and finally the symbol labeling the edge.
References
Restate the problem
In order to solve this, I’m going to implement a prefix-tree or “Trie” data structure in Python. I’ll focus on creating the structure, adding words, and crawling the trie because I won’t need to edit existing tries or delete nodes from tries to solve this challenge.
I need to build the data structure for the list of strings I get from Project Rosalind, then crawl the trie and produce the output format: parent node id, child node id, leading edge symbol.
Solution steps
At first, this seemed like a perfect use for Classes in Python.
I started by defining a Python class for each node.
class TrieNode:
def __init__(self, text = ''):
self.text = text
self.id = int
self.children = dict()
I made a class for Trie and class methods for creating a Trie from a list of strings, then crawling a Trie and returning a list of nodes in the required format (id, child_id, text).
I worked at this for the better part of a day, but could not get the crawling method to work and return correct results for the sample dataset, so I abandoned the approach and went back to a functional programming approach.
I leaned on Dan Halligan’s solution for guidance while I was writing my own code.
My first attempt at a full-sized dataset returned a correct result. The resulting Trie was large. The last node was:
8579 8580 T
Post-solution notes
Challenges solved so far: 56
How many people solved this before me: 1,422
Most recent solve before me: 10 days ago, and only 5 during the month of August 2025
Time spent on challenge: 7 hours
Most time-consuming facet: object-oriented approach
Questions from others: Most of the questions were about getting rid of whitespace and line breaks from the downloaded data, but I didn’t encounter any of that.
Solutions from others: My favorite object-oriented solution is short enough to include here.
class Trie:
available = 1
def __init__(self):
self.label = str(Trie.available)
self.child_nodes = defaultdict(Trie)
Trie.available += 1
def add_child(self, child):
if not child: return
self.child_nodes[child[0]].add_child(child[1:])
def print_trie(self):
for char,child in self.child_nodes.iteritems():
print self.label, child.label, char
child.print_trie()
T = Trie()
for s in data.read().split('\n'):
T.add_child(s)
T.print_trie()
submitted by Project Rosalind user abeliangrape.
Problem explanation: The problem explanation showed a functional approach, which surprised me some. I thought the object-oriented approach would be more officially proper.
Closing thoughts: After failing to implement a successful class implementation myself, I copied abeliangrape’s solution by typing it line-by-line myself, thinking through each step in an effort to teach myself the technique.